RNNAttensionで実装する作曲AI-推論編-【2022】

TIP
generative deep learningにて、生成型の機械学習の勉強をしている。その7章で作曲をAIで行う面白いプロジェクトがあったので、学習・推論を行った。前回学習を行ったので、今回は推論について記載する。なお、オンプレのGPU機にて学習・推論を行なっている。
WARNING
目次
前提
- pythonライブラリmusic21がインストール済みであること。
- musescore3がインストール済みであること。
- .music21が設定済みであること。
- cuda等GPUが使用できるよう設定済みであること。
- JupyterNotebookが使用できる環境であること。
ライブラリのインポート
ルックアップテーブル参照用のpickleや、推論用のRNNAttension、分析用のmatplotlib等をインポートする。
import pickle as pkl
import time
import os
import numpy as np
import sys
from music21 import instrument, note, stream, chord, duration
from models.RNNAttention import create_network, sample_with_temp
import matplotlib.pyplot as plt
パラメータとフォルダの設定
# run params
section = 'compose'
run_id = '0006'
music_name = 'cello'
run_folder = 'run/{}/'.format(section)
run_folder += '_'.join([run_id, music_name])
# model params
embed_size = 100
rnn_units = 256
use_attention = True
ルックアップテーブルのロード
学習時に保存していたdistincts,lookupsのパラメータをロードする。
store_folder = os.path.join(run_folder, 'store')
with open(os.path.join(store_folder, 'distincts'), 'rb') as filepath:
distincts = pkl.load(filepath)
note_names, n_notes, duration_names, n_durations = distincts
with open(os.path.join(store_folder, 'lookups'), 'rb') as filepath:
lookups = pkl.load(filepath)
note_to_int, int_to_note, duration_to_int, int_to_duration = lookups
モデルのビルド
学習した重みをロードして、モデルをビルドする。
weights_folder = os.path.join(run_folder, 'weights')
weights_file = 'weights.h5'
model, att_model = create_network(n_notes, n_durations, embed_size, rnn_units, use_attention)
# Load the weights to each node
weight_source = os.path.join(weights_folder,weights_file)
model.load_weights(weight_source)
model.summary()
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, None)] 0
__________________________________________________________________________________________________
input_2 (InputLayer) [(None, None)] 0
__________________________________________________________________________________________________
embedding (Embedding) (None, None, 100) 46100 input_1[0][0]
__________________________________________________________________________________________________
embedding_1 (Embedding) (None, None, 100) 1900 input_2[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, None, 200) 0 embedding[0][0]
embedding_1[0][0]
__________________________________________________________________________________________________
lstm (LSTM) (None, None, 256) 467968 concatenate[0][0]
__________________________________________________________________________________________________
lstm_1 (LSTM) (None, None, 256) 525312 lstm[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, None, 1) 257 lstm_1[0][0]
__________________________________________________________________________________________________
reshape (Reshape) (None, None) 0 dense[0][0]
__________________________________________________________________________________________________
activation (Activation) (None, None) 0 reshape[0][0]
__________________________________________________________________________________________________
repeat_vector (RepeatVector) (None, 256, None) 0 activation[0][0]
__________________________________________________________________________________________________
permute (Permute) (None, None, 256) 0 repeat_vector[0][0]
__________________________________________________________________________________________________
multiply (Multiply) (None, None, 256) 0 lstm_1[0][0]
permute[0][0]
__________________________________________________________________________________________________
lambda (Lambda) (None, 256) 0 multiply[0][0]
__________________________________________________________________________________________________
pitch (Dense) (None, 461) 118477 lambda[0][0]
__________________________________________________________________________________________________
duration (Dense) (None, 19) 4883 lambda[0][0]
==================================================================================================
Total params: 1,164,897
Trainable params: 1,164,897
Non-trainable params: 0
__________________________________________________________________________________________________
推論開始時のフレーズを指定する
あるフレーズから推論を開始するため、最初のフレーズを指定する。何も指定しないことも可能。
# prediction params
notes_temp=0.5
duration_temp = 0.5
max_extra_notes = 50
max_seq_len = 32
seq_len = 32
#notes = ['START', 'D3', 'D3', 'E3', 'D3', 'G3', 'F#3','D3', 'D3', 'E3', 'D3', 'G3', 'F#3','D3', 'D3', 'E3', 'D3', 'G3', 'F#3','D3', 'D3', 'E3', 'D3', 'G3', 'F#3']
#durations = [0, 0.75, 0.25, 1, 1, 1, 2, 0.75, 0.25, 1, 1, 1, 2, 0.75, 0.25, 1, 1, 1, 2, 0.75, 0.25, 1, 1, 1, 2]
#notes = ['START', 'F#3', 'G#3', 'F#3', 'E3', 'F#3', 'G#3', 'F#3', 'E3', 'F#3', 'G#3', 'F#3', 'E3','F#3', 'G#3', 'F#3', 'E3', 'F#3', 'G#3', 'F#3', 'E3', 'F#3', 'G#3', 'F#3', 'E3']
#durations = [0, 0.75, 0.25, 1, 1, 1, 2, 0.75, 0.25, 1, 1, 1, 2, 0.75, 0.25, 1, 1, 1, 2, 0.75, 0.25, 1, 1, 1, 2]
notes = ['START', 'C3', 'C3', 'G3', 'G3', 'A3', 'A3', 'G3']
durations = [0, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 1]
if seq_len is not None:
notes = ['START'] * (seq_len - len(notes)) + notes
durations = [0] * (seq_len - len(durations)) + durations
sequence_length = len(notes)
## 生成 一連のnotesに基づいてニューラルネットワークから新しいnotesを生成します
prediction_output = []
notes_input_sequence = []
durations_input_sequence = []
overall_preds = []
for n, d in zip(notes,durations):
note_int = note_to_int[n]
duration_int = duration_to_int[d]
notes_input_sequence.append(note_int)
durations_input_sequence.append(duration_int)
prediction_output.append([n, d])
if n != 'START':
midi_note = note.Note(n)
new_note = np.zeros(128)
new_note[midi_note.pitch.midi] = 1
overall_preds.append(new_note)
att_matrix = np.zeros(shape = (max_extra_notes+sequence_length, max_extra_notes))
for note_index in range(max_extra_notes):
prediction_input = [
np.array([notes_input_sequence])
, np.array([durations_input_sequence])
]
notes_prediction, durations_prediction = model.predict(prediction_input, verbose=0)
if use_attention:
att_prediction = att_model.predict(prediction_input, verbose=0)[0]
att_matrix[(note_index-len(att_prediction)+sequence_length):(note_index+sequence_length), note_index] = att_prediction
new_note = np.zeros(128)
for idx, n_i in enumerate(notes_prediction[0]):
try:
note_name = int_to_note[idx]
midi_note = note.Note(note_name)
new_note[midi_note.pitch.midi] = n_i
except:
pass
overall_preds.append(new_note)
i1 = sample_with_temp(notes_prediction[0], notes_temp)
i2 = sample_with_temp(durations_prediction[0], duration_temp)
note_result = int_to_note[i1]
duration_result = int_to_duration[i2]
prediction_output.append([note_result, duration_result])
notes_input_sequence.append(i1)
durations_input_sequence.append(i2)
if len(notes_input_sequence) > max_seq_len:
notes_input_sequence = notes_input_sequence[1:]
durations_input_sequence = durations_input_sequence[1:]
# print(note_result)
# print(duration_result)
if note_result == 'START':
break
overall_preds = np.transpose(np.array(overall_preds))
print('Generated sequence of {} notes'.format(len(prediction_output)))
Generated sequence of 82 notes
確信度をプロット
ヒートマップで作成した各notesの確信度をプロットする。
fig, ax = plt.subplots(figsize=(15,15))
ax.set_yticks([int(j) for j in range(35,70)])
plt.imshow(overall_preds[35:70,:], origin="lower", cmap='coolwarm', vmin = -0.5, vmax = 0.5, extent=[0, max_extra_notes, 35,70])

MIDIファイル生成・再生
予測からの出力をnotesに変換し、notesからMIDIファイルを作成する。
output_folder = os.path.join(run_folder, 'output')
midi_stream = stream.Stream()
# create note and chord objects based on the values generated by the model
for pattern in prediction_output:
note_pattern, duration_pattern = pattern
# pattern is a chord
if ('.' in note_pattern):
notes_in_chord = note_pattern.split('.')
chord_notes = []
for current_note in notes_in_chord:
new_note = note.Note(current_note)
new_note.duration = duration.Duration(duration_pattern)
new_note.storedInstrument = instrument.Violoncello()
chord_notes.append(new_note)
new_chord = chord.Chord(chord_notes)
midi_stream.append(new_chord)
elif note_pattern == 'rest':
# pattern is a rest
new_note = note.Rest()
new_note.duration = duration.Duration(duration_pattern)
new_note.storedInstrument = instrument.Violoncello()
midi_stream.append(new_note)
elif note_pattern != 'START':
# pattern is a note
new_note = note.Note(note_pattern)
new_note.duration = duration.Duration(duration_pattern)
new_note.storedInstrument = instrument.Violoncello()
midi_stream.append(new_note)
midi_stream = midi_stream.chordify()
timestr = time.strftime("%Y%m%d-%H%M%S")
midi_stream.write('midi', fp=os.path.join(output_folder, 'output-' + timestr + '.mid'))
'run/compose/0006_cello/output/output-20220426-225539.mid'
midi_stream.show('midi')
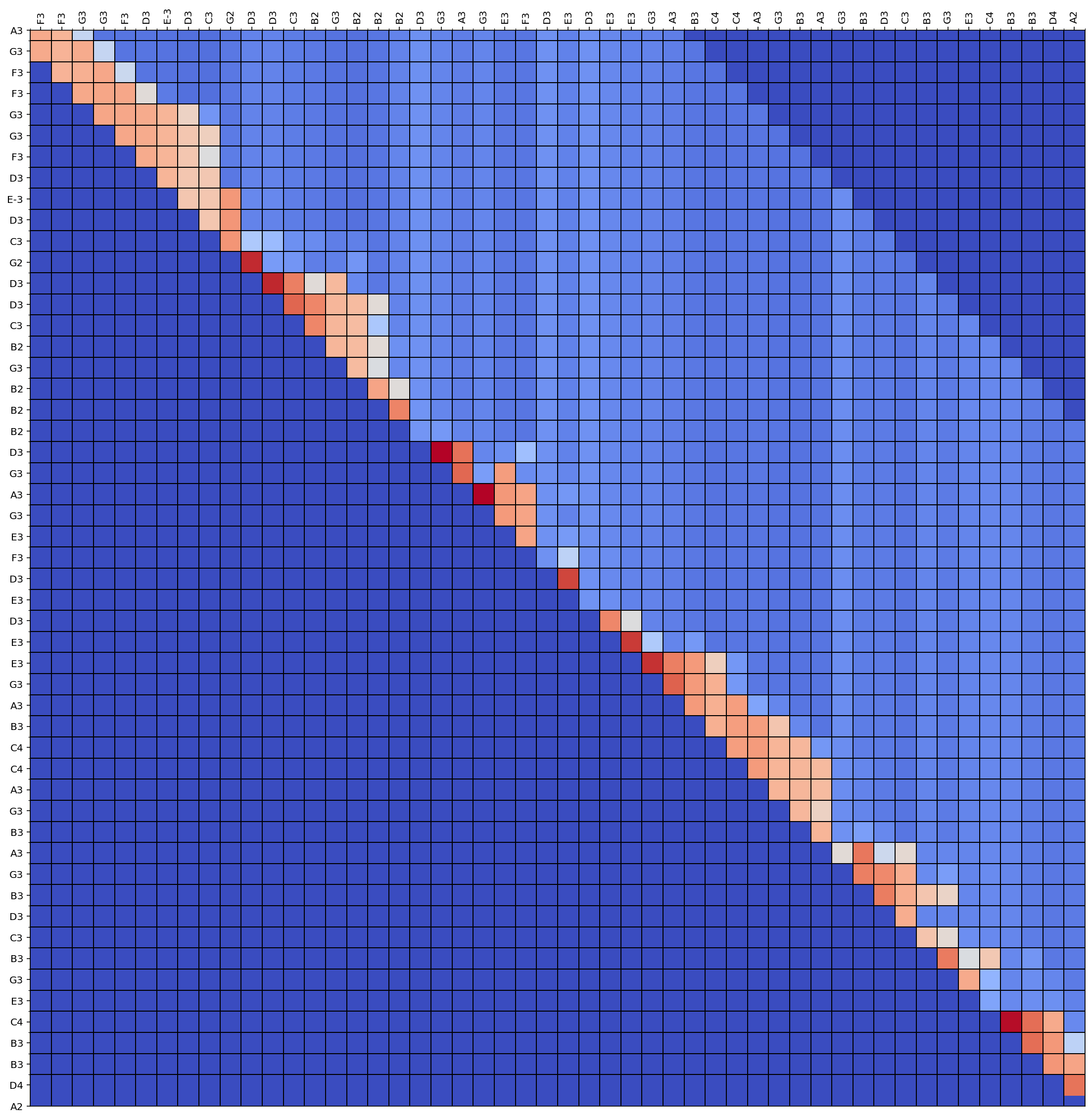
生成したnotesの確信度を確認
それぞれの推論notesの確信度をプロット
## attention plot
if use_attention:
fig, ax = plt.subplots(figsize=(20,20))
im = ax.imshow(att_matrix[(seq_len-2):,], cmap='coolwarm', interpolation='nearest')
# Minor ticks
ax.set_xticks(np.arange(-.5, len(prediction_output)- seq_len, 1), minor=True);
ax.set_yticks(np.arange(-.5, len(prediction_output)- seq_len, 1), minor=True);
# Gridlines based on minor ticks
ax.grid(which='minor', color='black', linestyle='-', linewidth=1)
# We want to show all ticks...
ax.set_xticks(np.arange(len(prediction_output) - seq_len))
ax.set_yticks(np.arange(len(prediction_output)- seq_len+2))
# ... and label them with the respective list entries
ax.set_xticklabels([n[0] for n in prediction_output[(seq_len):]])
ax.set_yticklabels([n[0] for n in prediction_output[(seq_len - 2):]])
# ax.grid(color='black', linestyle='-', linewidth=1)
ax.xaxis.tick_top()
plt.setp(ax.get_xticklabels(), rotation=90, ha="left", va = "center",
rotation_mode="anchor")
plt.show()