【機械学習】M1チップMacbook Airで手書き数字(MNIST)の分類【2022】
の分類【2022】)
TIP
今回は機械学習の復習も兼ねて、手書き数字の分類のお話。 また、個人で所有しているそこそこいいGPUの付いたゲームPCではなく、 M1チップを搭載したMacbook airでの学習・推論を行なった。
WARNING
目次
基本情報
まず、基本情報として、ニューラルネットワークとはなんなのか、というところからおさらいしておく。
ニューラルネットワークとは入力から出力への計算を行う小さなノードという計算単位の層――レイヤーを 複数重ねたニューラルネットワークを用いて分類・回帰などを行うことができるものである。
その構造は人間の脳を模して作られ、ニューラル(神経回路)という名前がついているのはそのためだ。
MNIST
今回使用するデータセットは0から9の手書き数字画像と正解ラベルを集めたもので、 6万件の訓練データと1万件のテストデータを含む、 28×28ピクセルのグレースケールの画像のデータセットである。
M1チップMacbook airでの環境構築
M1チップ搭載のMacbook等でのGPUを機械学習を行う方法として、 Miniforge3を使うものが知られている。
なお、2022年6月12日現在、筆者の知る限りではtensorflowはm1チップに対応しているが、 pytorchは対応していない――(はず) miniforge3については、以下公式githubよりダウンロードし、 インストールのスクリプトファイルを実行してガイドに適当に従うことでインストールできる。
https://github.com/conda-forge/miniforge
miniforge3を使う場合、仮想環境を作成し、 そこにライブラリをインストールすることを推奨する。
# 仮想環境作成
conda create -n ml python=3.9
# 仮想環境に入る
conda activate ml
# ライブラリを環境にインストール
conda install -c apple tensorflow-deps -y
python -m pip install tensorflow-macos
python -m pip install tensorflow-metal
ソースコードとその説明
それでは早速ソースコードとその説明に入っていこう。
パッケージのインポート
今回はtensorflowという機械学習のライブラリを使用する。
# パッケージのインポート
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Activation, Dense, Dropout
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
GPUが使えることを確認する
以下コードでmakbook airのgpuをtensorflowが認識できているかを確認できる。 GPU:0 とかが表示されていれば問題ない。
from tensorflow.python.client import device_lib
device_lib.list_local_devices()
Metal device set to: Apple M1
2022-06-13 00:23:07.319149: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:305] Could not identify NUMA node of platform GPU ID 0, defaulting to 0. Your kernel may not have been built with NUMA support.
2022-06-13 00:23:07.319258: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:271] Created TensorFlow device (/device:GPU:0 with 0 MB memory) -> physical PluggableDevice (device: 0, name: METAL, pci bus id: <undefined>)
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 14555634633964112980
xla_global_id: -1,
name: "/device:GPU:0"
device_type: "GPU"
locality {
bus_id: 1
}
incarnation: 11120825413590118757
physical_device_desc: "device: 0, name: METAL, pci bus id: <undefined>"
xla_global_id: -1]
データセットの確認
ここから、kerasのMNISTデータセットを利用し、読み込み、中身を確認していく。
# データセットの読み込み
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# データセットの形状の確認
print(train_images.shape)
print(train_labels.shape)
print(test_images.shape)
print(test_labels.shape)
(60000, 28, 28)
(60000,)
(10000, 28, 28)
(10000,)
# データセットの画像の確認
for i in range(10):
plt.subplot(1, 10, i+1)
plt.imshow(train_images[i], 'gray')
plt.show()
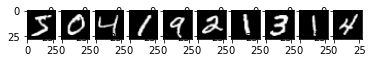
# 表示した画像に対し、正解ラベルを表示する。
print(train_labels[0:10])
[5 0 4 1 9 2 1 3 1 4]
データの形状の変形
ここから、モデルの入力形式に合わせてデータセットの形を変えていく。
今回のモデルの場合、一次元配列の要素数784に変形する。
# データセットの画像の前処理
train_images = train_images.reshape((train_images.shape[0], 784))
test_images = test_images.reshape((test_images.shape[0], 784))
# データセットの画像の前処理後のシェイプの確認
print(train_images.shape)
print(test_images.shape)
(60000, 784)
(10000, 784)
正解ラベルの変形
正解ラベルはone hot encoding(0と1で表現したベクトル)に変換する。 なお、今回のような分類問題の場合、予測値が一番高いものが予測結果となる。
tensorflow.keras.utilsのto_categorical関数を使えば、簡単にラベルをone hot encoding化できる。
# データセットのラベルの前処理
# 正解ラベルをone hot encodingに変換
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# データセットのラベルの前処理後のシェイプの確認
print(train_labels.shape)
print(test_labels.shape)
(60000, 10)
(10000, 10)
モデルの作成
ここから、モデルの作成に入っていく。
今回のモデルはユニット数256のsigmoid関数を活性化関数とした全結合層と
ユニット数128のsigmoid関数を活性化関数とした全結合層と
過学習を防ぐためのドロップアウト層と
ユニット数10のsoftmax関数を活性化関数とした全結合層をつなげたシンプルなモデルである。
# モデルの作成
model = Sequential()
model.add(Dense(256, activation='sigmoid', input_shape=(784,))) # 入力層
model.add(Dense(128, activation='sigmoid')) # 隠れ層
model.add(Dropout(rate=0.5)) # ドロップアウト
model.add(Dense(10, activation='softmax')) # 出力層
2022-06-13 00:23:16.973777: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:305] Could not identify NUMA node of platform GPU ID 0, defaulting to 0. Your kernel may not have been built with NUMA support.
2022-06-13 00:23:16.973843: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:271] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 0 MB memory) -> physical PluggableDevice (device: 0, name: METAL, pci bus id: <undefined>)
コンパイル
モデルを作成した後は、コンパイルを行う。
損失関数はcategorical_crossentropy、
最適化関数にはSGD、
評価指標にはacc(正解率)を用いた。
# コンパイル
model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=0.1), metrics=['acc'])
/Users/hiran0rm/miniforge3/envs/ml/lib/python3.9/site-packages/keras/optimizer_v2/gradient_descent.py:102: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.
super(SGD, self).__init__(name, **kwargs)
# 学習
history = model.fit(train_images, train_labels, batch_size=500,
epochs=20, validation_split=0.2)
Epoch 1/20
2022-06-13 00:23:20.162580: W tensorflow/core/platform/profile_utils/cpu_utils.cc:128] Failed to get CPU frequency: 0 Hz
2022-06-13 00:23:20.263216: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
96/96 [==============================] - 2s 9ms/step - loss: 1.7194 - acc: 0.4430 - val_loss: 0.9959 - val_acc: 0.8323
Epoch 2/20
9/96 [=>............................] - ETA: 0s - loss: 1.1507 - acc: 0.6738
2022-06-13 00:23:21.613395: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
96/96 [==============================] - 1s 8ms/step - loss: 0.9169 - acc: 0.7495 - val_loss: 0.5838 - val_acc: 0.8844
Epoch 3/20
96/96 [==============================] - 1s 8ms/step - loss: 0.6496 - acc: 0.8253 - val_loss: 0.4367 - val_acc: 0.9007
Epoch 4/20
96/96 [==============================] - 1s 8ms/step - loss: 0.5301 - acc: 0.8568 - val_loss: 0.3644 - val_acc: 0.9116
Epoch 5/20
96/96 [==============================] - 1s 8ms/step - loss: 0.4617 - acc: 0.8742 - val_loss: 0.3256 - val_acc: 0.9156
Epoch 6/20
96/96 [==============================] - 1s 8ms/step - loss: 0.4172 - acc: 0.8853 - val_loss: 0.3005 - val_acc: 0.9201
Epoch 7/20
96/96 [==============================] - 1s 8ms/step - loss: 0.3875 - acc: 0.8921 - val_loss: 0.2813 - val_acc: 0.9238
Epoch 8/20
96/96 [==============================] - 1s 8ms/step - loss: 0.3635 - acc: 0.8991 - val_loss: 0.2662 - val_acc: 0.9277
Epoch 9/20
96/96 [==============================] - 1s 8ms/step - loss: 0.3417 - acc: 0.9054 - val_loss: 0.2518 - val_acc: 0.9292
Epoch 10/20
96/96 [==============================] - 1s 8ms/step - loss: 0.3259 - acc: 0.9079 - val_loss: 0.2457 - val_acc: 0.9322
Epoch 11/20
96/96 [==============================] - 1s 8ms/step - loss: 0.3163 - acc: 0.9102 - val_loss: 0.2310 - val_acc: 0.9365
Epoch 12/20
96/96 [==============================] - 1s 8ms/step - loss: 0.2968 - acc: 0.9162 - val_loss: 0.2238 - val_acc: 0.9387
Epoch 13/20
96/96 [==============================] - 1s 8ms/step - loss: 0.2900 - acc: 0.9186 - val_loss: 0.2181 - val_acc: 0.9394
Epoch 14/20
96/96 [==============================] - 1s 8ms/step - loss: 0.2796 - acc: 0.9216 - val_loss: 0.2108 - val_acc: 0.9405
Epoch 15/20
96/96 [==============================] - 1s 8ms/step - loss: 0.2696 - acc: 0.9243 - val_loss: 0.2070 - val_acc: 0.9422
Epoch 16/20
96/96 [==============================] - 1s 8ms/step - loss: 0.2579 - acc: 0.9276 - val_loss: 0.2040 - val_acc: 0.9417
Epoch 17/20
96/96 [==============================] - 1s 8ms/step - loss: 0.2512 - acc: 0.9285 - val_loss: 0.2006 - val_acc: 0.9417
Epoch 18/20
96/96 [==============================] - 1s 8ms/step - loss: 0.2432 - acc: 0.9321 - val_loss: 0.1909 - val_acc: 0.9459
Epoch 19/20
96/96 [==============================] - 1s 8ms/step - loss: 0.2390 - acc: 0.9316 - val_loss: 0.1859 - val_acc: 0.9477
Epoch 20/20
96/96 [==============================] - 1s 8ms/step - loss: 0.2336 - acc: 0.9336 - val_loss: 0.1870 - val_acc: 0.9473
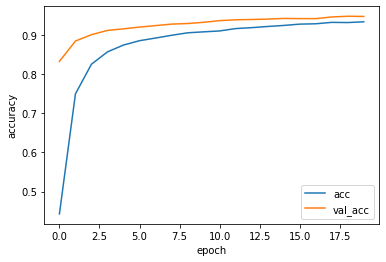
結果の表示
学習が終わったら、結果をグラフに出力する。
グラフへの出力には、matlotlibを使用する。
(綺麗さを求めるなら、seabornというライブラリを使用することをおすすめする)
# グラフの表示
plt.plot(history.history['acc'], label='acc')
plt.plot(history.history['val_acc'], label='val_acc')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.show()
評価
続いて、テストデータを使ってモデルの評価を行う。
(学習データとテストデータは、普通8:2程度の割合でランダムで分割することが多い)
# 評価
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('loss: {:.3f}\nacc: {:.3f}'.format(test_loss, test_acc ))
21/313 [=>............................] - ETA: 1s - loss: 0.1983 - acc: 0.9375
2022-06-13 00:23:49.747835: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
313/313 [==============================] - 2s 5ms/step - loss: 0.1869 - acc: 0.9448
loss: 0.187
acc: 0.945
推論
そして、最後にテストデータでの推論結果を視覚的に表示する。
推論した画像と、推論結果を並べ、 上で表示した正解率と差がないかを確認する。
# 推論する画像の表示
for i in range(10):
plt.subplot(1, 10, i+1)
plt.imshow(test_images[i].reshape((28, 28)), 'gray')
plt.show()
# 推論したラベルの表示
test_predictions = model.predict(test_images[0:10])
test_predictions = np.argmax(test_predictions, axis=1)
print(test_predictions)
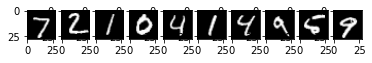
[7 2 1 0 4 1 4 9 6 9]
2022-06-13 00:23:56.199063: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
まとめ
最終的に、人間から見ても判断が難しい5の推論だけが間違っていて、 正解率の九割と大差ない結果となった。
今回は手書き数字認識(分類)の学習から推論までを、 M1チップMacbook airで実行した。
学習速度もかなり速く、 簡単な機械学習程度ならなんなくこなせるGPU性能がある。
何気無しにM1チップMacbook airを買って、 機械学習を試してみたいという方は是非、 Miniforge3で環境構築して、 tensorflowでM1チップの力を実感してみてほしい。
M2チップはM1チップより計算性能がもちろん上がっているとのことなので、 早く買いたい。でもそんな余裕はなかった。
というわけで今回はここまで。 ここまで読んだ方は読んでくれてありがとう。 また次回の記事でお会いしたい。