【機械学習】M1チップMacbook AirでCIFAR-10画像分類【2022】

TIP
- M1チップMacbook airのGPUを利用して、畳み込みニューラルネットワーク(CNN)で画像の分類を行ない、学習・推論速度の測定を行いました。
- 使用したデータセットはCIFAR-10という10種類の画像のデータセットです。
- M1チップMacbook airのGPU利用に関してはMiniforge3による構築で行い、ここについては前回の記事でも触れているため今回は省略します。
WARNING
目次
基本事項
まず、今回の計測にまつわる基本事項を解説します。
画像分類
画像分類とは、正解ラベルのある教師データを元に、データに対して画像の所属するクラスの分類を予測するタスクのことをいいます。
CIFAR-10
トレーニングデータ50000件、テストデータ10000件を含む10クラスの画像と正解ラベルを集めたデータセットです。正解クラスは以下の10種類。
| ID | 英語 | 日本語名 |
|---|---|---|
| 0 | airplane | 飛行機 |
| 1 | automobile | 自動車 |
| 2 | bird | 鳥 |
| 3 | cat | 猫 |
| 4 | deer | 鹿 |
| 5 | dog | 犬 |
| 6 | frog | カエル |
| 7 | horse | 馬 |
| 8 | ship | 船 |
| 9 | truck | トラック |
| もっと詳しい説明も英語ですが、公式HPにあり、ダウンロードもそこからできます。 | ||
| 公式HP http://www.cs.toronto.edu/~kriz/cifar.html |
畳み込みニューラルネットワーク
畳み込み層で特徴を抽出するニューラルネットワークで、画像などの特徴量が多いデータに対して有効とされています。畳み込み層の入力に対して、カーネル(フィルタ)をスライドさせて、カーネルと画像が重なった部分の和を計算します。このスライドの幅をストライドといいます。
何度も畳み込みを行う場合には、どんどん抽出した特徴が小さくなっていくので、外側に0を付加してサイズを行うパディングを行います。
また、特徴量のデータ量を圧縮するために、あるサイズの区間の最大値を取るMAXプーリングを行なったり、平均値を取るAverageプーリングを行うこともあります。
実装
それでは実装の解説に移っていきます。今回も実行はM1 Macbook Airを用いています。
パッケージのインポート
CIFAR-10はtensorflow内製のkerasのデータセットに含まれているので、そちらから読み込みます。 また機械学習のフレームワークとしてtensorflowを、そして行列の計算にnumpyを、 そして画像等のプロットに用いるため、matplotlibをインポートします。
# パッケージのインポート
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.layers import Activation, Dense, Dropout, Conv2D, Flatten, MaxPool2D
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.utils import plot_model
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
データセット読み込み・中身の確認
データセットを読み込んで、形状や中身を確認していきます。
# データセットの準備
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
# データセットのシェイプの確認
print(train_images.shape)
print(train_labels.shape)
print(test_images.shape)
print(test_labels.shape)
(50000, 32, 32, 3)
(50000, 1)
(10000, 32, 32, 3)
(10000, 1)
# データセットの画像の確認
plt.figure(figsize=(10,8))
plt.subplots_adjust(wspace=0.3, hspace=0)
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(train_images[i])
plt.show()

# データセットのラベルの確認
print(train_labels[0:10])
[[6]
[9]
[9]
[4]
[1]
[1]
[2]
[7]
[8]
[3]]
前処理
ニューラルネットワークに入力する前に、データセットの前処理を行います。 画像なので、255で割ることで一つ一つの要素が1を超えないようにします。 また、正解ラベルを10クラスのone hot表現に変換します。
# データセットの画像の前処理
train_images = train_images.astype('float32')/255.0
test_images = test_images.astype('float32')/255.0
# データセットの画像の前処理後のシェイプの確認
print(train_images.shape)
print(test_images.shape)
(50000, 32, 32, 3)
(10000, 32, 32, 3)
# データセットのラベルの前処理
train_labels = to_categorical(train_labels, 10)
test_labels = to_categorical(test_labels, 10)
# データセットのラベルの前処理後のシェイプの確認
print(train_labels.shape)
print(test_labels.shape)
(50000, 10)
(10000, 10)
モデルの作成
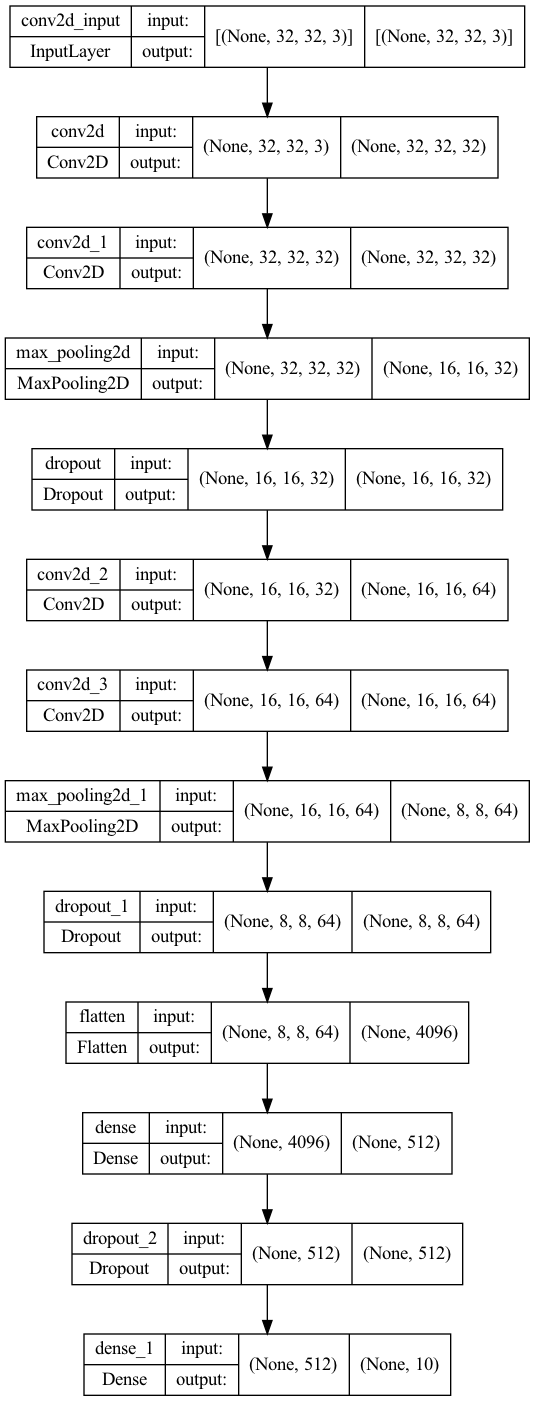
畳み込み層とプーリング層とドロップアウト層と全結合層などを重ね、モデルを作成し、コンパイルします。
#モデルの作成
model = Sequential()
# Conv→Conv→Pool→Dropout
model.add(Conv2D(32, (3, 3), activation='relu', padding='same', input_shape=(32, 32, 3)))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# Conv→Conv→Pool→Dropout
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# Flatten→Dense→Dropout→Dense
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
Metal device set to: Apple M1
2022-06-21 01:28:50.804765: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:305] Could not identify NUMA node of platform GPU ID 0, defaulting to 0. Your kernel may not have been built with NUMA support.
2022-06-21 01:28:50.805051: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:271] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 0 MB memory) -> physical PluggableDevice (device: 0, name: METAL, pci bus id: <undefined>)
# コンパイル
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])
/Users/hiran0rm/miniforge3/envs/ml/lib/python3.9/site-packages/keras/optimizer_v2/adam.py:105: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.
super(Adam, self).__init__(name, **kwargs)
# モデル構成をプロット
plot_model(model, show_shapes=True, expand_nested=True)
学習
続いて、コンパイルしたモデルで学習を行なっていきます。M1チップMacbook AirのGPUでの推論速度を確認するため、時間も測定しておきます。
# 学習
import time
now = time.time()
history = model.fit(train_images, train_labels, batch_size=128,
epochs=20, validation_split=0.1)
print(f"学習にかかった時間:{time.time()-now}[s]")
Epoch 1/20
2022-06-21 01:28:56.922811: W tensorflow/core/platform/profile_utils/cpu_utils.cc:128] Failed to get CPU frequency: 0 Hz
2022-06-21 01:28:57.095281: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
352/352 [==============================] - ETA: 0s - loss: 1.6246 - acc: 0.4075
2022-06-21 01:29:08.850139: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
352/352 [==============================] - 12s 34ms/step - loss: 1.6246 - acc: 0.4075 - val_loss: 1.2733 - val_acc: 0.5404
Epoch 2/20
352/352 [==============================] - 12s 33ms/step - loss: 1.1770 - acc: 0.5790 - val_loss: 1.0038 - val_acc: 0.6448
Epoch 3/20
352/352 [==============================] - 12s 34ms/step - loss: 0.9944 - acc: 0.6475 - val_loss: 0.8488 - val_acc: 0.7122
Epoch 4/20
352/352 [==============================] - 12s 33ms/step - loss: 0.8810 - acc: 0.6872 - val_loss: 0.7789 - val_acc: 0.7266
Epoch 5/20
352/352 [==============================] - 12s 34ms/step - loss: 0.7991 - acc: 0.7174 - val_loss: 0.7669 - val_acc: 0.7332
Epoch 6/20
352/352 [==============================] - 12s 34ms/step - loss: 0.7331 - acc: 0.7396 - val_loss: 0.7007 - val_acc: 0.7588
Epoch 7/20
352/352 [==============================] - 12s 34ms/step - loss: 0.6855 - acc: 0.7572 - val_loss: 0.6742 - val_acc: 0.7720
Epoch 8/20
352/352 [==============================] - 12s 34ms/step - loss: 0.6378 - acc: 0.7749 - val_loss: 0.6646 - val_acc: 0.7748
Epoch 9/20
352/352 [==============================] - 12s 34ms/step - loss: 0.5906 - acc: 0.7914 - val_loss: 0.6294 - val_acc: 0.7850
Epoch 10/20
352/352 [==============================] - 12s 34ms/step - loss: 0.5556 - acc: 0.8033 - val_loss: 0.6469 - val_acc: 0.7828
Epoch 11/20
352/352 [==============================] - 12s 34ms/step - loss: 0.5189 - acc: 0.8145 - val_loss: 0.6274 - val_acc: 0.7844
Epoch 12/20
352/352 [==============================] - 12s 34ms/step - loss: 0.4908 - acc: 0.8260 - val_loss: 0.6286 - val_acc: 0.7944
Epoch 13/20
352/352 [==============================] - 12s 34ms/step - loss: 0.4554 - acc: 0.8395 - val_loss: 0.6177 - val_acc: 0.8004
Epoch 14/20
352/352 [==============================] - 12s 34ms/step - loss: 0.4262 - acc: 0.8478 - val_loss: 0.6093 - val_acc: 0.8038
Epoch 15/20
352/352 [==============================] - 12s 33ms/step - loss: 0.4075 - acc: 0.8549 - val_loss: 0.6057 - val_acc: 0.8038
Epoch 16/20
352/352 [==============================] - 12s 33ms/step - loss: 0.3852 - acc: 0.8621 - val_loss: 0.6482 - val_acc: 0.7990
Epoch 17/20
352/352 [==============================] - 12s 34ms/step - loss: 0.3680 - acc: 0.8692 - val_loss: 0.6394 - val_acc: 0.8016
Epoch 18/20
352/352 [==============================] - 12s 34ms/step - loss: 0.3430 - acc: 0.8772 - val_loss: 0.6136 - val_acc: 0.8056
Epoch 19/20
352/352 [==============================] - 12s 33ms/step - loss: 0.3299 - acc: 0.8824 - val_loss: 0.6661 - val_acc: 0.8046
Epoch 20/20
352/352 [==============================] - 12s 34ms/step - loss: 0.3190 - acc: 0.8861 - val_loss: 0.6323 - val_acc: 0.8068
学習にかかった時間:237.9186029434204[s]
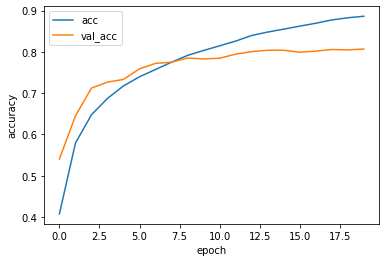
モデルの保存・学習の確認
学習の終わったモデルをh5形式で保存し、正解率の遷移をプロットします。
# モデルの保存
model.save('convolution.h5')
# グラフの表示
plt.plot(history.history['acc'], label='acc')
plt.plot(history.history['val_acc'], label='val_acc')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.show()
評価
テストデータでの推論結果(損失と正解率)を確認します。
# 評価
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('loss: {:.3f}\nacc: {:.3f}'.format(test_loss, test_acc ))
313/313 [==============================] - 3s 9ms/step - loss: 0.6922 - acc: 0.7858
loss: 0.692
acc: 0.786
推論
最後に、テストデータに対して、推論を行います。ついでに一枚あたりの推論時間も出しておきます。
# 推論する画像の表示
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(test_images[i])
plt.show()
# 推論したラベルの表示
now = time.time()
test_predictions = model.predict(test_images[0:10])
pred_time = time.time()-now
print(f"推論にかかった時間(10枚):{pred_time}[s]")
print(f"推論にかかった時間(1枚):{pred_time/10}[s]")
test_predictions = np.argmax(test_predictions, axis=1)
labels = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
print([labels[n] for n in test_predictions])

推論にかかった時間(10枚):0.07548689842224121[s]
推論にかかった時間(1枚):0.007548689842224121[s]
['cat', 'ship', 'ship', 'airplane', 'frog', 'frog', 'automobile', 'bird', 'cat', 'automobile']
2022-06-21 01:33:18.213022: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
まとめ
今回の記事のまとめです。
- M1チップMacbook AirのGPUを使ってtensorflowで畳み込みニューラルネットワークの学習と推論を行った。
- バッチサイズ128・エポック数20程度の学習終了までにかかった時間は238秒(4分)程度であった。
- 1枚の推論にかかる時間は 0.008秒程度であった。
- テストデータでの正解率は78%程度であった。 M1チップMacbook AirのGPUは結構使えますね。tensorflowはMacのM1チップに対応しているので、引き続きtensorflowとM1 Macbook Airで機械学習に挑戦していきたいと思います。